

Run this blog post as a Jupyter notebook on Renku

Summary
This blog presents LeafSim, an example-based explainable AI (XAI) technique for decision tree based ensemble methods. The process applies the Hamming distance on leaf indices to measure similarity between instances in the test and training set. It therefore explains model predictions by identifying training data points that most influenced a given prediction.
The proposed technique is:
- Easy to interpret by non-technical people
- Complementing existing XAI techniques
- Straightforward to implement & maintain in production
- Computationally lightweight
Introduction
This blog post will explore example-based XAI techniques. As such, the Articles will introduce an approach that aims to complement well-established techniques, such as SHAP and Lime. Specifically, the approach aims at explaining individual predictions of decision tree-based ensemble methods, such as Catboost, regardless of whether they are regressors or classifiers.
Existing XAI approaches, such as SHAP, provide insights into the most relevant features, both from a global and local perspective. In addition, they can provide perspective to predictions of individual data points, such as measuring how model predictions differ with varying feature values.
However, for people with limited knowledge in Machine Learning, it can be less intuitive to parse such information and build an understanding of what underpins model predictions.
In such cases, providing example-based explanations can be very helpful, as we outline in this blog post.
Data
A dataset on used cars has been selected to analyze the proposed approach and provide examples. It contains information such as mileage and selling price on roughly 100,000 used cars from various popular brands and is available on Kaggle (as of July 2022).

Predictors such as tax and miles per gallon were disregarded to simplify the analysis.
Clean data
The first and only cleaning step involves removing entries with unrealistic attributes (cars built in the future and those with an engine capacity of zero liters). Once completed, obtaining high-level summaries of the considered attributes is now possible.

A few interesting insights stand out from these histograms:
- Only a tiny fraction of cars are EVs or hybrids.
- Most of the cars are sold at prices close to \(£10,000\).
- Ford cars are the most popular ones, especially considering that the brand “focus” is most likely referring to a car model produced by Ford, namely Ford Focus.
While a more thorough analysis may reveal more, data exploration and preparation are outside the scope of this blog post and therefore have not been explored.
Task
With a grasp of the data, let us imagine ourselves in the shoes of a car dealer, who must decide, based on some relevant car properties, at what price to sell it. To support car dealers, we will provide them with an automated tool that suggests an indicative, initial price point based on the prices of historically sold cars. Such a tool is assumed to simulate how car dealers naturally set prices, by looking at prices that similar cars fetched.
Model
To solve the defined task, a Catboost Regressor is chosen. However, really any ensemble method of decision trees could be used.
For modeling, near default hyperparameters are used (only slightly modifying the number of estimators and size of leaves), and the data is randomly split in a 80-20 fashion.

The results above suggest the model performs reasonably well as, on average, it is only off by about 9% and tends to slightly over-predict the actual price (ca. 1% higher on average).
Again, the goal here is not to develop the best-performing model, but to ensure that it accomplishes the task with reasonable accuracy and that no overfitting occurs.
Now that the model is trained, we can turn to state-of-the-art XAI techniques to make this black box more transparent.
SHAP
Lime and SHAP are popular tools and, in many aspects, very similar. However, as the objective is to describe their common shortcomings, we will only focus on SHAP.
SHAP can be used to obtain global insights into what features are most important and how they affect the predictions of a model. A concrete example would be obtaining the most critical features in terms of their average, absolute contributions to the model predictions. These predictions are often visualized using the built-in bar plot provided by SHAP.

Here, we can see that the engine size is by far the most relevant attribute when it comes to predicting car sale prices (with an average absolute impact of \(approx £ 3,100\).
Similarly, the beeswarm plot is useful to gauge not only the impact but also the sign of the contribution.

We can see that larger engine sizes (higher feature values, coloured in red) are related to higher predictions of sales prices (larger SHAP value).
However, SHAP can also be used to obtain local explanations, i.e. explain the prediction of a particular instance, in our case a specific car we want to sell.
Consider the following car for which we would like to determine the sales price:

To get some insight into what affected the decision of the model, we can use the popular waterfall plot:

The plot shows the influence of selected features on the model prediction \(f(x)\) for this specific car compared to the average prediction of all the cars in the training set \(E[ f(X)]\).
Concretely, the model expects the average car to sell for \(E[f(X)] \approx 16,000\), while it predicts the selected car to sell for \( f(x) \approx 31,000 \). A major reason that the model estimates the price of this car to be higher than that of the average is its \(3\) litre, engine size, which translates into an increase above the mean expected sales price of \(\approx 12,500 \).
However, the above explanations might not be intuitive for car dealers. They may not be interested in an explanation referencing the average car as it is not clear what the average car is without some insights into the dataset (see histograms in the Data section). Instead, it might be more relevant to understand how this prediction compares to similar cars sold in the past.
To address this, we propose an approach to find similar training instances, i.e., those on which the model mainly bases its prediction. This way, car dealers can directly gauge the observed sales prices of similar cars, allowing them to put those into perspective and understand from where a predicted price stems.
To this end, we introduce our example-based XAI technique named LeafSim.
LeafSim
The proposed approach only works for decision trees and their ensemble derivatives, such as the popular Catboost algorithm. It leverages how such models are built to easily extract similar training instances for a given prediction we wish to explain.
More specifically, each decision tree partitions the feature space through a series of binary questions. Each question is a branch. If a branch is not followed by another question, it is colloquially known as a leaf. Leaves are determined based on a chosen convergence criteria, such as RMSE for regression. Further, leaves provide predictions based on the training observations ending up in them. For regression, for example, these predictions are based on the average target value of those observations.
This entire process is succinctly summarised in the following image from the Encyclopedia of Machine Learning, which visualises the case of regression using two predictor variables.
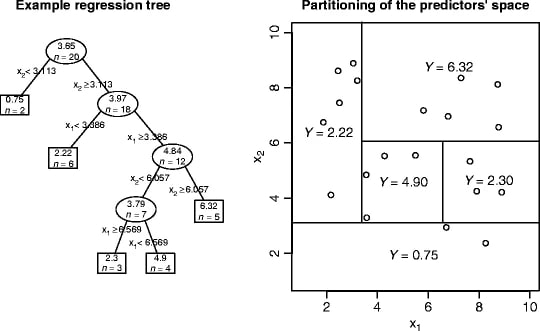
Here, the squared boxes refer to the leaves; their associated prediction value is simply the average \(Y\) value of the observations falling into them.
Based on this understanding of how decision trees are built and how they operate, itbecomes evident that two data points ending up in the same leaf have very similar features (by satisfying the same conditions as imposed by binary questions that create branches) and similar targets (by satisfying the convergence criteria of leaves).
Thus, we define similar instances as those that end up most often in the same leaf across all decision trees in an ensemble. Hence the name LeafSim. This approach is loosely related to , which introduced LeafRefit to rank training instances based on the change in loss for a given test instance.Visually, LeafSim can be represented as follows:

Here, \(x_{test}\) is the instance for which we want to explain the prediction and \(X_{train}\) are all the instances in the training data, with \(x_i\) being an individual observation (in our case a car).
Similarity can thus be measured using the Hamming distance. Briefly, the Hamming distance captures, for two strings of equal length, the number of positions for which the symbols differ. This allows us to measure the number of times leaf indices differ across trees. By dividing this number by the number of trees and subtracting it from \(1\), we can transform it into a bounded similarity metric.
Implementation
In the case of Catboost, LeafSim can easily leverage the built-in function calc_leaf_indexes to obtain the leaf indices. For XGBoost the equivalent would be the function apply.
For those who wish to learn more about the implementation of LeafSim and access the code used in this blog post, please refer to the Renku repository.
Examples
To understand how these LeafSim scores can be utilized, let us start by analysing two concrete examples.
Example 1
As a first example, we will pick the BMW that we previously used to explain SHAP, and as this is a common brand and model, we expect the model to make a reasonably accurate prediction.

The table above describes the attributes of our selected car alongside the model prediction and the car's actual sale price.
We can see that the model provides an accurate prediction, but we would like to understand which cars in the training set this prediction is mostly based on.
For simplicity, we restrict ourselves to the Top 10 cars with the highest LeafSim score, i.e., the ten cars that appear most often in the same leaf as the car we want to explain. This choice depends on how fast LeafSim scores drop in the ranking. If there is minimal change, then showing a large subset of the most similar observations will lead to redundant information.
The Top 10 cars are described in the table below.

The colours in the table represent how similar the cars are to the car we want to explain. The lighter the shade of red of a cell, the more similar the two cars are in this respect, while the darker the shade of blue in the similarity column is, the more similar the two cars.
We can see that for the most important features, the provided cars are indeed very similar. Their sale prices are also very much in line with the selected car's predicted sale price.
In the above table, we have restricted the data to the Top 10. However, we could also investigate the relationship between price and the LeafSim score across the entire training set, as is shown in the following plot on the left.

The prices of cars with a higher LeafSim score vary less and are generally closer to the prediction of the car we want to explain.
To put the LeafSim score of this particular car in perspective, the plot on the right shows the distribution of the average LeafSim score for the Top 50 training instances. We can see that this car has several similar training instances (the mean LeafSim score of the Top 50 is roughly 80%). This indicates the model is basing its prediction on very relevant training samples and therefore the prediction can be assumed to be fairly accurate.
The choice of 50 here is somewhat arbitrary and data-dependent. It should be a value that equals the number of observations we can typically expect to be highly similar. Predictions with few similar training instances should stand out.
Example 2
As a second example, let us pick an electric car. As these are drastically under-represented in the dataset, the model will perform poorly on them.

Indeed, the error rate of EVs is roughly 3x larger than for any other fuel type.
Let us pick a specific electric car:

We already see that the predicted price is quite different from the actual price.
However, we do not know the actual price in a real-world setting as car dealers will use the tool to set the selling price; thus, the car has not yet been sold. To better understand what this prediction is based on and whether one can fully trust it, we can again turn to the most similar training examples as identified by LeafSim.

In this case, we can clearly see that the most similar training instances are not very close to the predicted car.
The LeafSim scores are low (below 50%) and crucial attributes vary considerably, such as brand, model, and fuel type.

We also see from the above plot on the left, that there is a lot of price variation, even for the most similar cars. From the plot on the right we can clearly see that the average LeafSim scores of the most related training instances are very low.
Therefore, car dealers should lower their confidence in the model prediction for this particular car.
Conclusion
In this blog post, we addressed the interpretability gap of popular XAI techniques, such as SHAP and Lime, regarding their use by people with limited knowledge in Machine Learning.
Specifically, an example-based approach to explain decision-tree based ensemble methods was proposed, identifying the most relevant instances in the training set on which the model bases a particular prediction.
This measure of relevance is expressed using the LeafSim score, which captures how often observations end up in the same leaf.
Mainly through a qualitative assessment of selected examples, we demonstrated that the LeafSim score indeed reflects similarity between observations. Furthermore, the model tends to predict observations with higher LeafSim scores more accurately. Therefore, end-users can use such scores to adjust their confidence in model predictions.
Acknowledgements
The author would like to thank his colleagues at Richemont and SDSC, namely Elvire Bouvier, Francesco Calabrese and Valerio Rossetti for their support in developing LeafSim and for their valuable feedback when writing this blog post.
References
Appendix
Technical considerations
Each tree has the same weight in LeafSim, which may not be the most faithful approach depending on the Machine Learning method we would like to explain. However, empirical results for gradient boosting show that giving equal weights to all trees provides useful and insightful results.
About the author






