
Open-source RAG for Zurich SMEs
Canton Zurich AI Program generates a Retrieval-Augmented Generation prototype for SMEs

Abstract
As part of the Canton Zurich SME AI Program, nine companies joined forces in a collaborative prototyping to design and build a Retrieval-Augmented Generation (RAG) system for regulatory compliance. Rather than working on separate solutions, participants jointly developed a shared architecture, learning from one another while tackling a concrete, realistic scenario: enabling a packaging company to navigate heterogeneous documentation to meet sustainability compliance requirements. The outcome is a functional, open-source AI framework, together with a set of shared design principles that any of the participating organizations can reuse, extend and adapt to address their own operational and regulatory needs.
People
Collaborators

Paulina Körner joined the SDSC in September 2025 as a Data Scientist in the Innovation team in Zurich.
Paulina holds an MSc in Environmental Science from ETH Zürich and completed an MPhil in Machine Learning and Machine Intelligence at the University of Cambridge. She has worked as a data science intern in Alpine Remote Sensing and as a research assistant at ETH Zürich, where she focused on automating chemical risk evaluations. She also gained consulting experience at South Pole, supporting clients in designing decarbonization roadmaps. Paulina is particularly interested in interpretable machine learning and in applying AI to address real-world challenges in environmental science, industry, and the public sector.

Ivan-Daniel joined the SDSC Innovation team in September 2022, where he works as a Data Scientist. He obtained an MSc in Robotics (2022) from EPFL and holds a BSc in Microengineering (2019), also from EPFL. His main fields of interest are Machine Learning, Computer Vision, and animal locomotion modeling.

Thibaut holds a B.Sc in Computer Science from HEIG-VD. Before joining the SDSC, he worked in startups where he developped a diverse skill set combining cloud infrastructure, database and application development. Thibaut is very enthusiatic about new technologies and best coding practices and he is looking forward to supporting the team and its projects.

Anna joined SDSC as a Data Scientist focusing on industry collaborations in July 2019. She completed her PhD in Bioinformatics at the University of Luxembourg, where she analysed large-scale heterogeneous datasets and leveraged multiple disciplines: Statistics, Network Analysis, and Machine Learning. Before joining SDSC, Anna worked as a Data Scientist at Deloitte Luxembourg, with a focus on computer vision and time-series analysis.Currently, Anna is a Principal Data Scientist based at the ETH Zurich office, where she leads biomedical collaborations with industry partners. Anna works on a range of projects: protein properties prediction, biomanufacturing optimization, statistical model evaluation and others.
PI | Partners:
Canton of Zurich | Department of Economics:
Markus Müller
Raphael von Thiessen
Chantal Stäuble
Anna Zakharova
Collaborating SMEs
- Cisra: Janine Plüss
- DATABIOMIX: Marco Meola
- Econetta AG: Adelene Lai
- LanguageMasters GmbH : Gosia Kubat, Alma Thalmann
- Microdul AG: Roger Leimer
- SOORT AG: Wolfgang Loerli
- StratoServ Sciences AG: Detty Berta
- Swiss Safety Center AG: Marco Induti
- Vonlanthen INSIGHT: Patrik Vonlanthen
description
Motivation
The central question underlying the collaborative use case was: How can we design RAG systems that provide reliable outputs when the available evidence and data are incomplete, contradictory, or of uneven quality?
To address this, the nine SMEs participating in the AI Innovation Program of the Canton of Zurich identified seven practical challenges that arise when deploying AI in compliance-sensitive or regulated environments:
- Bringing knowledge together: important information is often spread across many different documents, formats and systems. Collecting and organizing this information into a reliable knowledge base is the first major challenge.
- Finding the right information: Specialized language and complex questions make it difficult to consistently identify the most relevant information needed to accurately answer a query.
- Trustworthy and transparent answers: Every answer must be based on verifyable sources, clearly reference where the information comes from, and avoid unsupported or fabricated claims.
- Reliable and consistent results: The system must produce results that are consistent, measurable, and dependable enough for real-world, production-ready use, not just demonstrations.
- Structured and usable outputs: Results need to be delivered in formats that fit existing business processes, reports, and software systems, rather than as unstructured text alone.
- Understanding user questions: People often ask questions that are vague, incomplete, or depend on context. The system must interpret these questions correctly to retrieve the right information.
- Meeting regulatory compliance: In regulated industries, AI systems must provide clear records of how decisions are made and comply with governance, traceability, and audit requirements.
Solution
The prototype implemented a full end-to-end RAG pipeline covering five core stages: chunking, embedding, storage, retrieval, and answer generation. On top of this shared framework, four feature tracks were developed in parallel, allowing all nine companies to contribute to and benefit from a common architecture simultaneously:
· Track 1 introduced an evaluation infrastructure from the outset, with metrics for faithfulness, answer relevancy, context precision, and context recall, alongside a synthetic question-answer dataset for scalable testing.
· Track 2 enforced a structured JSON (Java Script Object Notation) response format so that every answer included explicit source references and suggested follow-up questions, making the outputs transparent, auditable, and ready for integration into downstream applications and business processes.
· Track 3 implemented and compared advanced retrieval strategies including semantic vector search, keyword search, and hybrid retrieval with Reciprocal Rank Fusion, as well as query expansion and conversational context management for complex multi-turn questions.
· Track 4 extended the system toward agentic workflows, enabling the model to reason across multiple steps, decompose complex questions, compare sources independently, and identify missing evidence before generating a final answer.
All components were implemented as modular, swappable building blocks within an editable Python library (conversational-toolkit) complemented with a use-case-specific application layer. This architecture makes it easy to add, replace, or customize components without rewriting the underlying system.
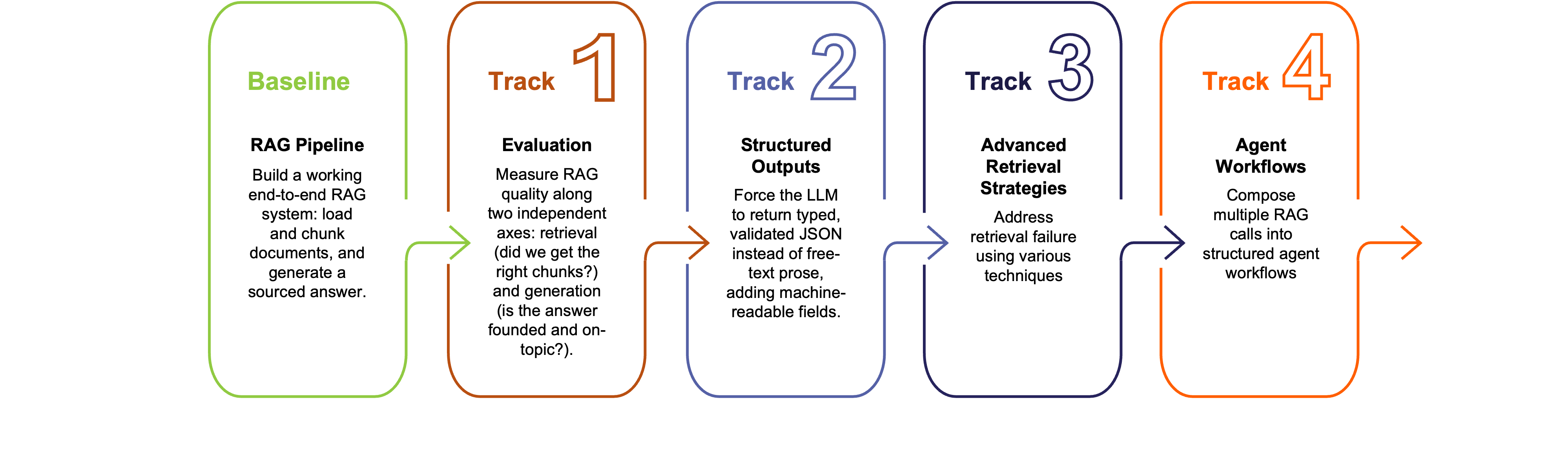
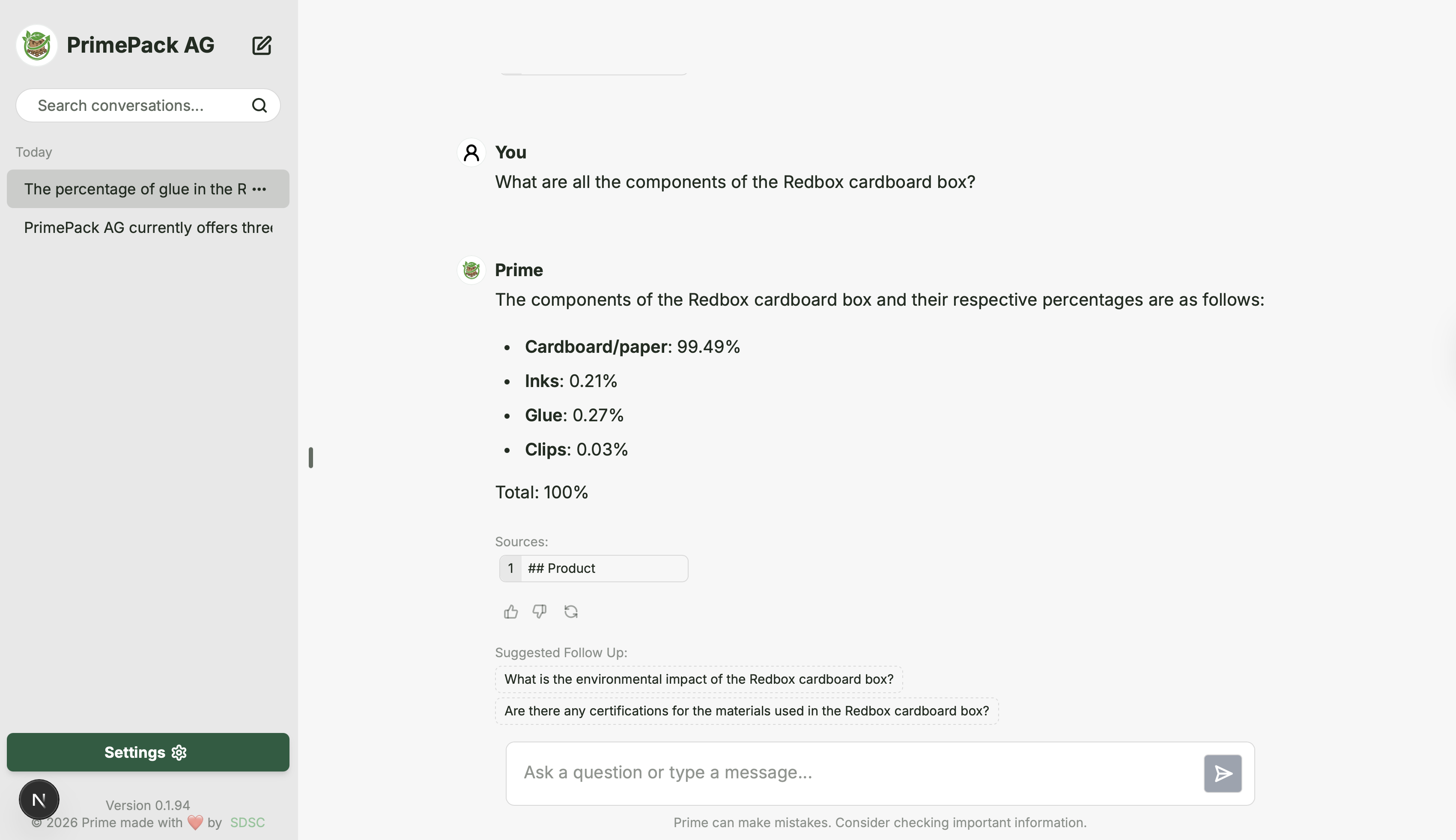
Figure 2. RAG prototype frontend (PrimePack AG use case), SME AI Program in the Canton of Zürich (February–March 2026).
Impact
The project showed that modular, evidence-aware RAG systems can be developed using open-source tools and shared infrastructure. More importantly, it demonstrated the value of collaborative prototyping as a way to learn, test ideas, and build common understanding across organizations.
Participants not only created a working prototype, but also developed a shared understanding of good design principles for RAG systems. These include building evaluation infrastructure early, combining multiple retrieval methods, separating stronger and weaker evidence, and structuring outputs to make answers transparent and auditable.
The resulting open-source prototype, codebase, and notebooks now provide participants with a practical reference architecture that can be reused and extended for future applications.
Open-source code available
The RAG prototype is available for SMEs open-source and maintained by the SDSC on GitHub:
https://github.com/SwissDataScienceCenter/sme-kt-zh-collaboration-rag
Presentation
Gallery
Annexe
Additional resources
Bibliography
Publications
More projects

Timeseries Forecasting for Business Impact
CHUV: Heracles - Sepsis Model

AI-Driven Political Monitoring

LUCID National Data Stream
News
Latest news

Coding the Future: Energy Data Hackdays Expand to French-speaking Switzerland
Coding the Future: Energy Data Hackdays Expand to French-speaking Switzerland

Science des données : le SDSC et le Canton de Vaud soutiennent quatre projets appliqués
Science des données : le SDSC et le Canton de Vaud soutiennent quatre projets appliqués

Le Swiss Data Science Center inaugure son siège au Biopôle de Lausanne
Le Swiss Data Science Center inaugure son siège au Biopôle de Lausanne
Contact us
Let’s talk Data Science
Do you need our services or expertise?
Contact us for your next Data Science project!